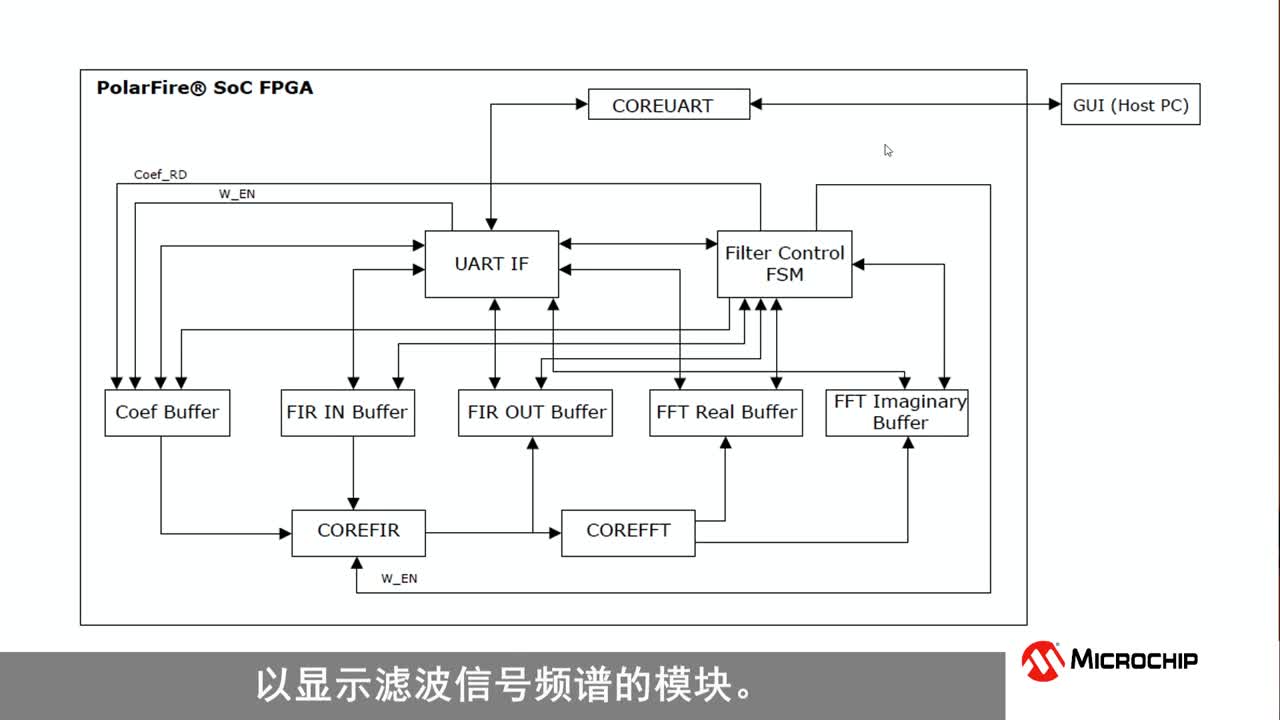
|
快速傅里葉變換(FFT)作為計算和分析工具,在眾多學科領域(如信號處理、圖像處理、生物信息學、計算物理、應用數學等)有著廣泛的應用。在高速數字信號處理領域,如雷達信號處理,FFT的處理速度往往是整個系統設計性能的關鍵所在。 針對高速實時信號處理的要求,軟件實現方法顯然滿足不了其需要。近年來現場可編程門陣列(FPGA)以其高性能、高靈活性、友好的開發環境、在線可編程等特點,使得基于FPGA的設計可以滿足實時數字信號處理的要求,在市場競爭中具有很大的優勢。 在FFT算法中,數據的寬度通常都是固定的寬度。然而,在FFT的運算過程中,特別是乘法運算中,運算的結果將不可避免地帶來誤差。因此,為了保證結果的準確性,采用定點分析是非常必要的。 1 FFT算法原理 FFT算法的基本思想就是利用權函數的周期性、對稱性、特殊性及周期N的可互換性,將較長序列的DFT運算逐次分解為較短序列的DFT運算。針對N=2的整數次冪,FFT算法有基-2算法、基-4算法、實因子算法和分裂基算法等。這里,從處理速度和占用資源的角度考慮,選用基-4按時間抽取FFT算法 (DIT)。對于N=4γ,基-4 DIT具有log4N=γ次迭代運算,每次迭代包含N/4個蝶形單元。蝶形單元的運算表達式為: 其信號流如圖1。式中:A,B,C,D和A′,B′,C′,D′均為復數據;W=e-j2π/N。進行1次蝶形運算共需3次復乘和8次復加運算。N=64 點的基-4DIT信號流其輸入數據序列是按自然順序排列的,輸出結果需經過整序。64點數據只需進行3次迭代運算,每次迭代運算含有N/4=16個蝶形單元。 2 FFT算法的硬件實現 2.1 流水線方式FFT算法的實現 為了提高FFT工作頻率和節省FPGA資源,采用3級流水線結構實現64點的FFT運算。流水線處理器的結構如圖2所示。 每級均由延時單元、轉接器(SW)、蝶形運算和旋轉因子乘法4個模塊組成,延時節拍由方框中的數字表示。各級轉接器和延時單元起到對序列進行碼位抽取并將數據拉齊的作用。每級延時在FPGA內部用FIFO實現,不需要對序列進行尋址即可實現延時功能。數據串行輸入,經過3級流水處理后,串行輸出。 轉接器有一定的工作規律。例如,當第0級變換做完進入轉接器SW1前,先對后三路數據進行一定節拍的延時,延遲節拍分別為4,8,12。為了說明規律,把輸入轉接器的四路數據按照前后次序進行分組,每4個時鐘節拍為1組,共16組,如圖3(左)所示。在數據流串行經過轉接器SW1時,第0組中的數據保持不變,第1組中的數據與第4組中的數據交換;5不變,2和8交換,3和12交換,6和9交換;10不變,7和13交換,11和14交換,15不變。交換完畢后,前三路數據經過延遲節拍分別為12,8,4的FIFO存儲器輸出,位置關系如圖3所示。 上述轉換規律對于SW2也是適用的,只是轉接器前后的延時節拍和分組的大小有所不同。 2.2 存儲單元 為了實現算法的流水線設計,存儲器RAM設計為64×16 b的雙端口RAM,即在時鐘信號和寫控制信號同時為低電平時,從輸入總線寫入RAM;在時鐘信號和讀控制信號同時為高電平時,從RAM輸出數據。 ROM為17×16 b的ROM,儲存經過量化后的旋轉因子,旋轉因子為正弦函數和余弦函數的組合。根據旋轉因子的對稱性和周期性,在利用ROM存儲旋轉因子時,可以只存儲旋轉因子的一部分。 2.3 運算結構 Radix-4蝶形運算單元是整個FFT處理器中的核心部件。在用Radix-4運算器計算時需要并行輸入數據,如果能以并發數據輸入的話,則同步性和控制度較好,但實際上常要進行串并之間的轉換。存儲RAM按單節拍輸出16 b位寬數據,選擇器不停旋轉送入到確定的位置,每4點全部到位后R-4使能有效;然后4個時鐘節拍得到有效結果數據,再通過選擇器旋轉送入到對應存儲 RAM中。 復數運算中,對應復數的實部和虛部RAM用同一個地址發生器。地址發生器在進行RAM地址發生時采用兩套地址,第一套是計數器按時鐘節拍順序產生的,用于輸入數據的存儲;第二套是由數據寬度為16 b的ROM產生的,ROM中存放的數據為下級運算所需倒序的序列地址,發生地址給RAM,然后RAM按倒序地址輸出下級需要進行運算的數據。 2.4 塊浮點結構 數字信號處理系統可分為定點制、浮點制和塊浮點制,它們在實現時對系統資源的要求不同,工作速度也不同,有著不同的適用范圍。定點制算法簡單,速度快,但動態范圍有限,需要用合適的溢出控制規則(如定比例法)適當壓縮輸入信號的動態范圍。浮點表示法動態范圍大,可避免溢出,但系統實現復雜,硬件需求量大,速度慢。 為了提高精度,并減少復雜度和存儲量,采用塊浮點結構。塊浮點算法是以上兩種表示法的結合。這種表示方法是,一組數共用同一個階碼,這個階碼是這組數中最大數的階碼。塊浮點算法無需進行額外的指數運算,僅對尾數進行運算即可,其與定點運算一樣方便,但需要在每級運算結束后進行本級運算溢出最大位數判斷,以對數據塊進行塊指數調整。在調整時僅保留一位符號位,因而能夠充分利用有限位長。這樣處理比定點方法擴大了動態范圍,并且提高了精度,比浮點運算在速度上有了提高。塊浮點結構如圖4所示。 3 結 語 著重討論基于FPGA的64點高速FFT算法的實現方法。采用高基數結構和流水線結構,大大提高了FFT處理器的運行速度。同時塊浮點結構的引入,也大幅減少了浮點操作占用FPGA器件的資源數目,兼顧了FPGA高精度、低資源、低功耗的特點。從實驗結果看,該方法可以滿足高速實時處理數字信號的要求。 |